
Modelos QAT Gemma 3 do Google Democratizam a IA Avançada para Hardware de Consumo
O Google lançou versões quantizadas de seu poderoso modelo de linguagem Gemma 3 27B QAT, permitindo que a IA de ponta seja executada em hardware de consumo. As novas variantes de Treinamento com Percepção de Quantização (QAT, na sigla em inglês) reduzem drasticamente os requisitos de memória, mantendo um desempenho comparável ao de suas contrapartes de precisão total, marcando uma virada ao trazer recursos avançados de IA para dispositivos pessoais.

Trazendo o Poder de Supercomputadores para GPUs de Consumo
Em um pequeno apartamento no Brooklyn, a desenvolvedora de software Maya Chen executa geração complexa de imagens de IA e análise de texto que normalmente exigiria serviços de nuvem caros ou hardware especializado. O segredo dela? Uma placa de vídeo NVIDIA RTX 3090 de dois anos executando o modelo Gemma 3 27B QAT recém-lançado do Google.
"É revolucionário", explica Chen ao demonstrar o sistema. "Estou executando o que equivale a IA de nível de supercomputador em hardware que já possuía. Antes deste lançamento, simplesmente não era possível."
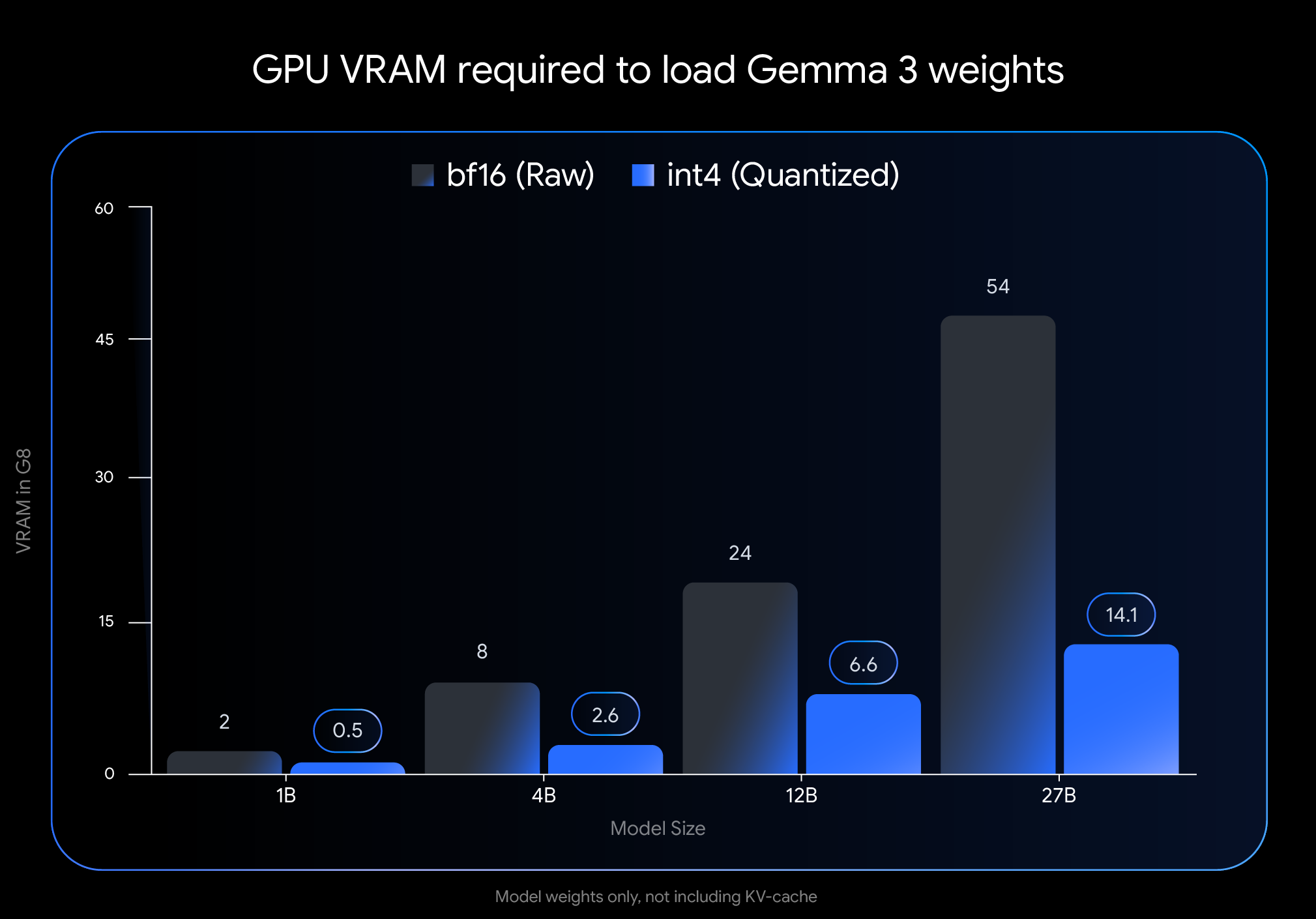
A experiência de Chen reflete a promessa do anúncio do Google em 18 de abril: democratizar o acesso à IA de ponta, tornando-a eficiente em hardware de consumo amplamente disponível. O lançamento do Gemma 3 no mês passado o estabeleceu como um modelo aberto líder, mas seus altos requisitos de memória limitavam a implantação a hardware caro e especializado. As novas variantes QAT mudam essa dinâmica completamente.
Avanço Técnico na Compressão de Modelos
Os modelos quantizados representam um avanço técnico na compressão de modelos de IA. As abordagens tradicionais para reduzir o tamanho do modelo geralmente resultavam em uma degradação significativa do desempenho, mas a implementação do Google de Treinamento com Percepção de Quantização introduz uma nova abordagem.
Ao contrário dos métodos convencionais de quantização pós-treinamento, o QAT incorpora o processo de compressão durante a própria fase de treinamento. Ao simular operações de baixa precisão durante o treinamento, os modelos se adaptam para funcionar de forma otimizada, mesmo quando implantados com precisão numérica reduzida.
"O que torna essa abordagem particularmente eficaz é a metodologia de treinamento", observa um pesquisador de aprendizado de máquina que analisou os modelos. "Ao aplicar QAT em aproximadamente 5.000 etapas e usar probabilidades de checkpoints não quantizados como alvos, eles reduziram a queda de perplexidade em 54% em comparação com as técnicas de quantização padrão."
O impacto nos requisitos de memória é dramático. A pegada de VRAM do modelo Gemma 3 27B encolhe de 54 GB para apenas 14,1 GB – uma redução de quase 74%. Da mesma forma, a variante de 12B cai de 24 GB para 6,6 GB, a de 4B de 8 GB para 2,6 GB e a de 1B de 2 GB para meros 0,5 GB.
Essas reduções tornam os modelos antes inacessíveis viáveis em hardware de consumo. O modelo 27B principal agora é executado confortavelmente em GPUs de desktop como a NVIDIA RTX 3090, enquanto a variante 12B pode operar de forma eficiente em GPUs de laptop como a NVIDIA RTX 4060.
Desempenho no Mundo Real Valida Abordagem
O que separa a implementação do Google de tentativas anteriores de quantização de modelos é o impacto mínimo no desempenho. Benchmarks independentes sugerem que os modelos QAT mantêm a precisão dentro de 1% de suas contrapartes de precisão total.
Nas classificações Chatbot Arena Elo, uma medida amplamente respeitada do desempenho do modelo de IA com base nas preferências humanas, os modelos Gemma 3 obtêm pontuações impressionantemente altas. A variante 27B atinge uma pontuação Elo de 1338, colocando-a entre os principais modelos abertos, apesar de exigir significativamente menos poder de computação do que os concorrentes.
O feedback da comunidade corrobora essas métricas oficiais. Usuários em fóruns de desenvolvedores relatam que os modelos QAT "parecem mais inteligentes" do que outras variantes quantizadas. Em comparações diretas usando a desafiadora métrica GPQA diamond, o Gemma 3 27B QAT superou outros modelos quantizados enquanto usava menos memória.
"Vimos tempos de resposta quase instantâneos em aplicações em tempo real", diz um desenvolvedor que integrou o modelo em um aplicativo móvel. "Isso torna o Gemma 3 prático para implantações de ponta, onde a latência e as restrições de recursos são fatores críticos."
Capacidades Multimodais Expandem Casos de Uso
Além do desempenho bruto, o Gemma 3 incorpora inovações arquitetônicas que expandem suas capacidades além do processamento de texto. A integração de um codificador de visão permite que os modelos processem imagens junto com o texto, embora alguns especialistas observem limitações na profundidade da compreensão visual em comparação com sistemas especializados maiores.
Outro avanço significativo é o suporte para janelas de contexto estendidas – até 128.000 tokens para a maioria das variantes e 32.000 para o modelo 1B. Isso permite que a IA processe documentos e conversas muito mais longos do que a maioria dos modelos acessíveis ao consumidor.
"A implementação de um mecanismo de atenção local/global intercalado reduz drasticamente a pegada de memória necessária para a inferência de contexto longo", explica um engenheiro de aprendizado de máquina familiarizado com a arquitetura. "Isso torna viável o processamento de documentos extensos em GPUs de consumo sem sacrificar a compreensão."
Suporte ao Ecossistema Facilita Adoção
O Google priorizou a facilidade de integração, lançando os modelos em formatos compatíveis com ferramentas de desenvolvedor populares. Os modelos QAT não quantizados int4 e Q4_0 oficiais estão disponíveis no Hugging Face e no Kaggle, com suporte nativo de ferramentas incluindo Ollama, LM Studio, MLX para Apple Silicon, Gemma.cpp e llama.cpp.
Este suporte ao ecossistema acelerou a adoção entre desenvolvedores e pesquisadores independentes. Os fóruns de discussão estão cheios de relatos de implantações bem-sucedidas em diversas configurações de hardware e casos de uso.
"O amplo suporte a ferramentas e o processo de configuração fácil foram cruciais", diz um desenvolvedor que integrou o modelo em um aplicativo educacional. "Conseguimos implantar localmente em horas, eliminando os custos da nuvem e mantendo a qualidade da resposta."
Limitações e Direções Futuras
Apesar dos avanços, os especialistas identificam várias áreas onde os modelos Gemma 3 ainda enfrentam limitações. Embora possam processar contextos longos, alguns usuários observam que a capacidade de raciocinar profundamente em entradas muito extensas permanece desafiadora, particularmente para tarefas analíticas complexas.
O componente de visão, embora eficiente, não é tão sofisticado quanto em alguns modelos multimodais maiores e treinados em conjunto. Isso pode afetar o desempenho em tarefas que exigem compreensão visual sutil.
Além disso, alguns pesquisadores de aprendizado de máquina apontam que grande parte do desempenho do Gemma 3 vem da destilação sofisticada de conhecimento de modelos de professores mais poderosos, provavelmente da família Gemini proprietária do Google. Essa dependência, juntamente com alguma opacidade na metodologia pós-treinamento, limita a reprodutibilidade total pela comunidade de pesquisa de IA mais ampla.
Democratizando o Desenvolvimento de IA
O lançamento representa um passo significativo para tornar os recursos avançados de IA acessíveis a uma gama mais ampla de desenvolvedores, pesquisadores e entusiastas. Ao permitir a implantação local em hardware comum, os modelos Gemma 3 QAT reduzem as barreiras de entrada em termos de custo e requisitos técnicos.
"Isso é mais do que apenas capacidades técnicas", reflete Chen, o desenvolvedor do Brooklyn. "É sobre quem pode inovar com essas tecnologias. Quando a IA poderosa é executada localmente em hardware de consumo, ela abre portas para indivíduos e pequenas equipes que não podiam pagar por uma infraestrutura especializada."
À medida que a IA influencia cada vez mais vários aspectos do desenvolvimento de tecnologia, a capacidade de executar modelos sofisticados localmente pode ser transformadora para a inovação além das principais empresas de tecnologia. A abordagem do Google com o Gemma 3 QAT sugere um futuro onde a IA de ponta se torna uma ferramenta democratizada em vez de um recurso centralizado.
Se essa visão se materializar totalmente depende de como a tecnologia evolui e de como a comunidade de desenvolvedores mais ampla abraça essas capacidades. Por enquanto, no entanto, a lacuna entre a pesquisa de IA de ponta e a implantação prática diminuiu significativamente – um desenvolvimento com implicações potencialmente de longo alcance para o futuro da acessibilidade da IA.