
ByteDance Apresenta Seed 1.5-VL: Um Modelo de IA de Visão-Linguagem Revolucionário que Rivaliza com o Gemini Pro 2.5
Em um grande avanço para a inteligência artificial multimodal, a equipe Seed da ByteDance lançou seu mais recente modelo grande de visão-linguagem, o Seed 1.5-VL, marcando um marco significativo na corrida global por IA. Projetado com apenas 20 bilhões de parâmetros ativados, o Seed 1.5-VL entrega um desempenho comparável ao Gemini 2.5 Pro do Google, estabelecendo referências de ponta (SOTA - State-of-the-Art) em um amplo espectro de tarefas visuais e interativas do mundo real — tudo com custos de inferência substancialmente reduzidos.
🚀 O Que Aconteceu?
Em 15 de maio de 2025, a ByteDance lançou oficialmente o Seed 1.5-VL, a mais recente evolução em sua série Seed de modelos de IA multimodal. Pré-treinado com mais de 3 trilhões de tokens de dados multimodais de alta qualidade — incluindo texto, imagens e vídeos — o Seed 1.5-VL combina raciocínio visual avançado, compreensão de imagem, interação com interface gráfica (GUI) e análise de vídeo em uma única arquitetura simplificada.
Ao contrário de sistemas de IA inchados, o Seed 1.5-VL utiliza uma arquitetura Mixture of Experts (MoE), ativando apenas um subconjunto de seus 20 bilhões de parâmetros totais para cada tarefa. Isso melhora drasticamente a eficiência computacional, tornando-o ideal para aplicações de IA interativas em tempo real em ambientes de desktop, mobile e embarcados.
Apesar de seu tamanho relativamente compacto, o Seed 1.5-VL entregou resultados SOTA em 38 dos 60 benchmarks de avaliação públicos, incluindo:
- 14 de 19 benchmarks de compreensão de vídeo
- 3 de 7 tarefas de agente de GUI
Em testes, ele se destacou em raciocínio complexo, reconhecimento óptico de caracteres (OCR), interpretação de imagem, detecção de vocabulário aberto e análise de vídeo de segurança.
O Seed 1.5-VL já está publicamente disponível para testes através da API do Volcano Engine e para a comunidade de código aberto no Hugging Face e GitHub.
📌 Pontos Chave
- Domínio Multimodal: Lida com tarefas de imagem, vídeo, texto e GUI com compreensão de nível humano.
- Eficiência em Primeiro Lugar: Apenas 20 bilhões de parâmetros ativos, oferecendo resultados comparáveis ao Google Gemini 2.5 Pro com custos mais baixos.
- Conquistas SOTA: Lidera em 38 dos 60 benchmarks públicos, especialmente em tarefas de vídeo e GUI.
- Aplicações Práticas: Já testado em OCR, análise de vigilância, reconhecimento de celebridades e interpretação de imagens metafóricas.
- Acesso Aberto: API disponível no Volcano Engine, artigo técnico no arXiv e código no GitHub.
🔍 Análise Detalhada
Arquitetura e Inovações
O Seed 1.5-VL é construído em três módulos principais:
- Encoder Visual SeedViT: Um encoder de 532 milhões de parâmetros que extrai características ricas de imagens e quadros de vídeo.
- Adaptador MLP: Faz a ponte entre o encoder visual e o modelo de linguagem, traduzindo características de imagem/vídeo em tokens multimodais.
- Modelo Grande de Linguagem: Um LLM baseado em MoE com 20 bilhões de parâmetros, otimizado para eficiência de inferência.
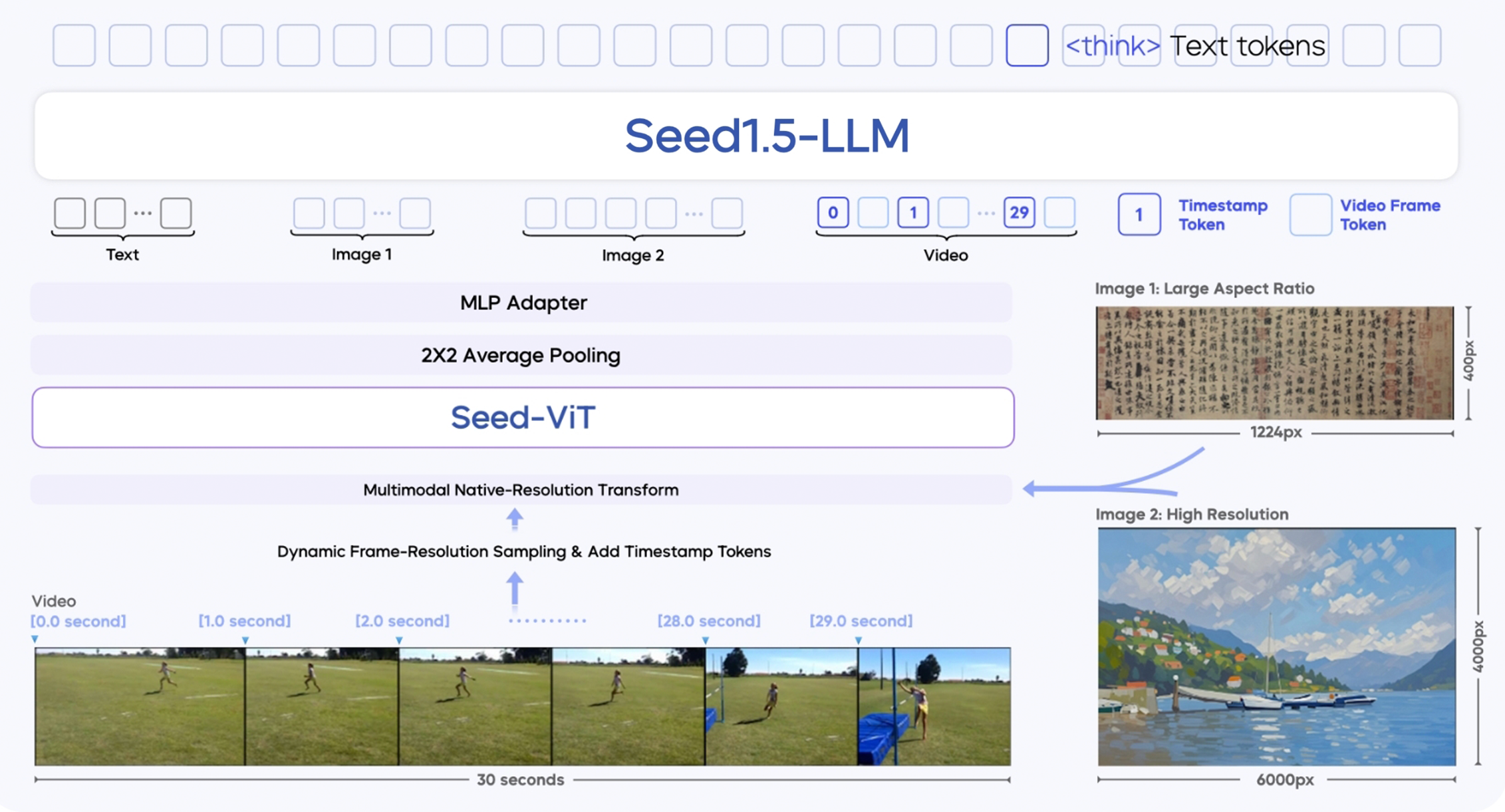
Ele introduz diversas inovações técnicas:
- Suporte a entrada multi-resolução: Mantém a qualidade e a precisão da imagem.
- Amostragem dinâmica de quadros por resolução: Melhora a compreensão de vídeo selecionando quadros com base na complexidade do movimento.
- Aprimoramento temporal via tokens de timestamp: Melhora o rastreamento de sequências de objetos e causalidade em vídeos.
- Treinamento em 3T+ tokens multimodais: Melhora a generalização entre domínios.
- Refinamentos pós-treinamento: Inclui amostragem de rejeição e aprendizado por reforço online para ajustar a qualidade da resposta.
Pontos Fortes
O Seed 1.5-VL se destaca em:
- Resposta a Perguntas Visuais (VQA) e interpretação de gráficos
- Tarefas de automação de GUI, incluindo jogos e controle de aplicativos
- Raciocínio interativo em ambientes visuais abertos
- Aplicações do mundo real, como identificação de celebridades, vigilância e compreensão de metáforas
Ele é elogiado pela robustez no mundo real, algo que muitos modelos acadêmicos carecem. Vários revisores até o rotularam de "potência não convencional" capaz de competir com o o4 da OpenAI e o Gemini do Google.

Limitações
Apesar de seus pontos fortes, o Seed 1.5-VL não é perfeito:
- Desafios visuais detalhados: Tem dificuldades com contagem de objetos sob oclusão, similaridade de cores ou arranjos irregulares.
- Raciocínio espacial complexo: Tarefas como navegar em labirintos ou resolver quebra-cabeças de encaixe podem gerar resultados incompletos.
- Inferência temporal: Dificuldades surgem ao rastrear sequências de ações entre quadros.
Essas são áreas que a ByteDance reconhece e provavelmente está focando em futuras iterações.
Contexto Competitivo
O Seed 1.5-VL é lançado em meio a uma corrida armamentista de IA:
- O Gemini 2.5 Pro do Google (6 de maio de 2025) domina os rankings multimodais (LMArena).
- Os modelos o3 e o4-mini da OpenAI (17 de abril de 2025) impulsionam o uso de ferramentas multimodais e o aprendizado por reforço.
- Concorrentes locais como Tencent e Doubao aprimoraram capacidades de imagem e voz.
Analistas de investimento estão otimistas: modelos agentes e capacidades multimodais são vistos como principais impulsionadores de aplicações de IA de próxima geração, particularmente em software empresarial, ERP, OA (Automação de Escritório), assistentes de codificação e ferramentas de escritório.
💡 Você Sabia?
- O Seed 1.5-VL pode detectar comportamento suspeito em vídeos de vigilância — um caso de uso avançado no mundo real que poucos modelos abordam de forma eficaz.
- É um dos poucos modelos capazes de ler imagens metafóricas e explicar relacionamentos abstratos dentro delas.
- Apenas 3 modelos globalmente (Gemini Pro 2.5, OpenAI o4, Seed 1.5-VL) são atualmente capazes de controle interativo, cross-modal de GUI em tempo real.
- A ByteDance conseguiu rivalizar o desempenho do Gemini Pro usando muito menos parâmetros, demonstrando habilidades de compressão e otimização de modelo de elite.
- O Seed 1.5-VL usa uma transformação nativa que preserva a resolução, evitando a degradação de qualidade comum em encoders de visão tradicionais.
Considerações Finais
O Seed 1.5-VL marca um marco importante para a ByteDance em se estabelecer como uma líder global em pesquisa de IA, particularmente em modelos fundamentais multimodais. Com eficiência de desempenho inigualável, capacidade robusta no mundo real e conquistas SOTA em benchmarks chave, não está apenas acompanhando empresas como Google e OpenAI — está competindo de frente.
À medida que a adoção da IA se aprofunda em diversas indústrias, modelos como o Seed 1.5-VL estarão na vanguarda — moldando agentes inteligentes, impulsionando a automação e redefinindo o que as máquinas podem perceber, entender e fazer.
Editor CTOL Ken: Recomendo fortemente conferir os exemplos na página oficial do Seed 1.5-VL da ByteDance — eles são realmente impressionantes.