
Como Escolher GPUs para Deep Learning e Modelos de Linguagem Grandes
Ao selecionar GPUs para cargas de trabalho de deep learning, especialmente para treinar e executar modelos de linguagem grandes (LLMs), vários fatores precisam ser considerados. Aqui está um guia completo para fazer a escolha certa.
Tabela: Últimos LLMs Open Source Líderes e Seus Requisitos de GPU para Implantação Local
| Modelo | Parâmetros | Requisito de VRAM | GPU Recomendada |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1,342GB | NVIDIA A100 80GB ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7GB | NVIDIA RTX 3060 12GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5GB | NVIDIA RTX 3080 10GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9GB | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7GB | NVIDIA RTX 4090 24GB ×2 |
| Llama 3 70B | 70B | ~140GB (estimado) | Série NVIDIA 3000, mínimo 32GB RAM |
| Llama 3.3 (modelos menores) | Varia | Pelo menos 12GB VRAM | Série NVIDIA RTX 3000 |
| Llama 3.3 (modelos maiores) | Varia | Pelo menos 24GB VRAM | Série NVIDIA RTX 3000 |
| GPT-NeoX | 20B | 48GB+ VRAM total | Duas NVIDIA RTX 3090s (24GB cada) |
| BLOOM | 176B | 40GB+ VRAM para treinamento | NVIDIA A100 ou H100 |
Principais Considerações ao Escolher GPUs
1. Requisitos de Memória
- Capacidade de VRAM: Talvez o fator mais crítico para LLMs. Modelos maiores exigem mais memória para armazenar parâmetros, gradientes, estados do otimizador e amostras de treino em cache.
** Tabela: Importância da VRAM em Modelos de Linguagem Grandes (LLMs).**
| Aspecto | Papel da VRAM | Por que é Crucial | Impacto se Insuficiente |
|---|---|---|---|
| Armazenamento do Modelo | Armazena pesos e camadas do modelo | Necessário para processamento eficiente | Descarrega para memória mais lenta; grande queda de performance |
| Cálculo Intermediário | Armazena ativações e dados intermediários | Permite passes de forward/backward em tempo real | Limita paralelismo e aumenta latência |
| Processamento em Lotes | Suporta tamanhos de lote maiores | Melhora a vazão (throughput) e a velocidade | Lotes menores; treinamento/inferência mais lenta |
| Suporte a Paralelismo | Permite paralelismo de modelo/dados entre GPUs | Necessário para modelos muito grandes (ex: GPT-4) | Limita a escalabilidade entre várias GPUs |
| Largura de Banda da Memória | Oferece acesso a dados de alta velocidade | Acelera operações de tensor como multiplicações de matrizes | Gargalos em tarefas com alta demanda de computação |
- Calcule Suas Necessidades: Você pode estimar os requisitos de memória com base no tamanho do seu modelo e no tamanho do lote.
- Largura de Banda da Memória: Uma largura de banda maior permite a transferência de dados mais rápida entre a memória da GPU e os núcleos de processamento.
2. Poder de Processamento
- CUDA Cores: Mais cores geralmente significam processamento paralelo mais rápido.
- Tensor Cores: Especializados para operações de matriz (tensor math), cruciais para tarefas de deep learning.
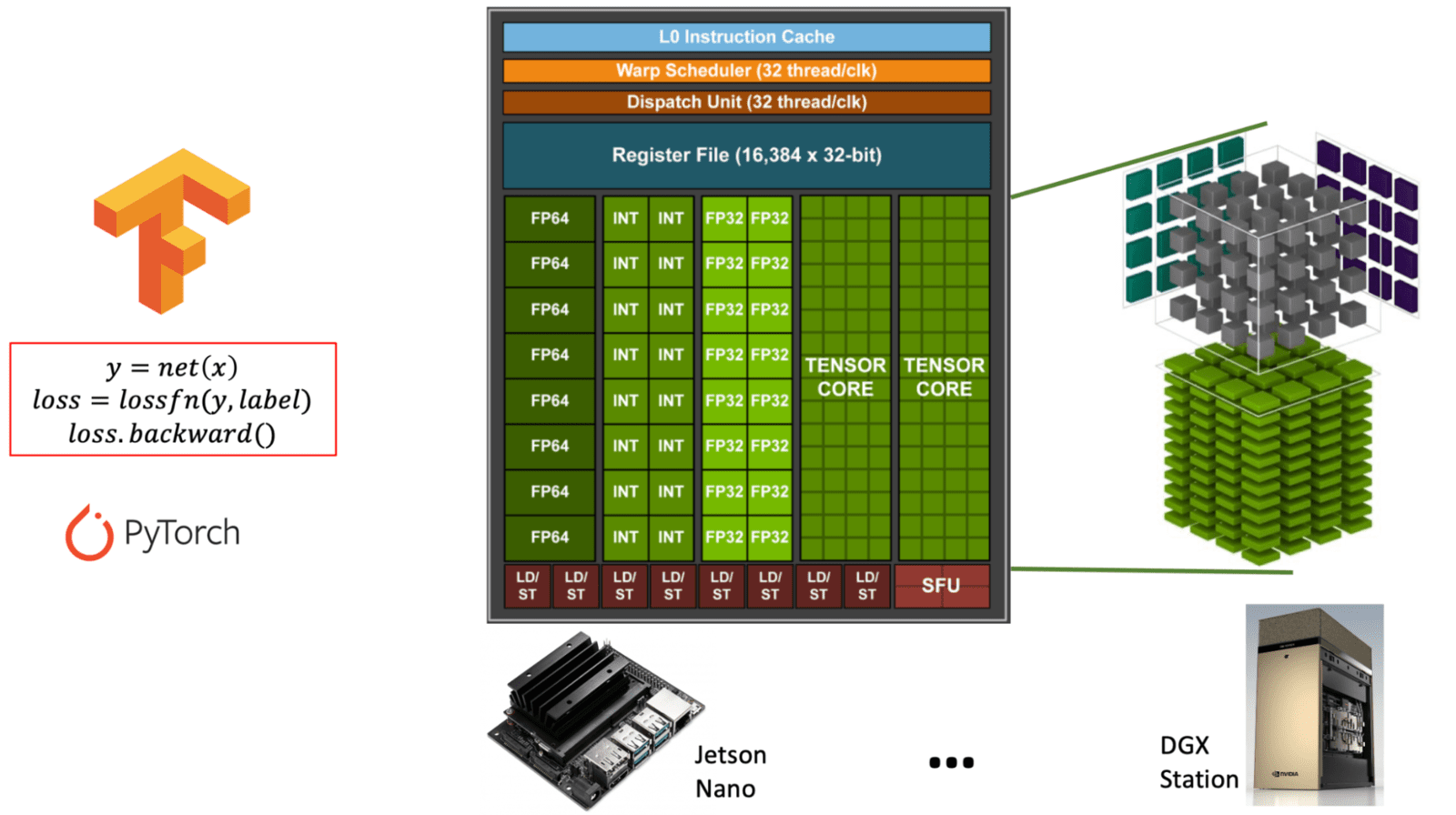
Diagrama ilustrando a diferença entre os núcleos CUDA de propósito geral e os núcleos Tensor especializados dentro da arquitetura de uma GPU NVIDIA. (learnopencv.com) - Suporte a FP16/INT8: O treinamento com precisão mista pode acelerar significativamente os cálculos enquanto reduz o uso de memória.
** Tabela: Comparação de CUDA Cores vs. Tensor Cores em GPUs NVIDIA. Esta tabela explica o propósito, a função e o uso de CUDA cores versus Tensor Cores, que são ambos essenciais para diferentes tipos de cargas de trabalho de GPU, especialmente em IA e deep learning. **
| Funcionalidade | CUDA Cores | Tensor Cores |
|---|---|---|
| Propósito | Computação de propósito geral | Especializados para operações de matriz (tensor math) |
| Uso Principal | Gráficos, física e tarefas paralelas padrão | Tarefas de deep learning (treinamento/inferência) |
| Operações | FP32, FP64, INT, aritmética geral | Multiplicação-acumulação de matriz (ex: FP16, BF16, INT8) |
| Suporte a Precisão | FP32 (single), FP64 (double), INT | FP16, BF16, INT8, TensorFloat-32 (TF32), FP8 |
| Desempenho | Desempenho moderado para tarefas de propósito geral | Desempenho extremamente alto para tarefas intensivas em matrizes |
| Interface de Software | Modelo de programação CUDA | Acessado via bibliotecas como cuDNN, TensorRT, ou frameworks (ex: PyTorch, TensorFlow) |
| Disponibilidade | Presente em todas as GPUs NVIDIA | Presente apenas em arquiteturas mais recentes (Volta e posteriores) |
| Otimização para IA | Limitado | Altamente otimizado para cargas de trabalho de IA (até 10x+ mais rápido) |
3. Comunicação Entre GPUs
- NVLink: Se estiver usando configurações multi-GPU, o NVLink oferece comunicação GPU a GPU significativamente mais rápida do que o PCIe.
NVLink é uma tecnologia de interconexão de alta velocidade desenvolvida pela NVIDIA para permitir comunicação rápida entre GPUs (e às vezes entre GPUs e CPUs). Ela aborda as limitações do PCIe tradicional (Peripheral Component Interconnect Express), oferecendo largura de banda e latência significativamente maiores.
** Tabela: Visão Geral da Ponte NVLink e Seu Propósito. Esta tabela descreve a função, os benefícios e as principais especificações do NVLink no contexto da computação baseada em GPU, especialmente para IA e cargas de trabalho de alto desempenho. **
| Funcionalidade | NVLink |
|---|---|
| Desenvolvedor | NVIDIA |
| Propósito | Permite comunicação rápida e direta entre múltiplas GPUs |
| Largura de Banda | Até 600 GB/s total em versões recentes (ex: NVLink 4.0) |
| Comparado ao PCIe | Muito mais rápido (PCIe 4.0: ~64 GB/s total) |
| Latência | Menor que a do PCIe; melhora a eficiência multi-GPU |
| Casos de Uso | Deep learning (LLMs), computação científica, renderização |
| Como Funciona | Usa uma ponte NVLink (conector de hardware) para conectar GPUs |
| GPUs Suportadas | GPUs NVIDIA de ponta (ex: A100, H100, RTX 3090 com limites) |
| Software | Funciona com aplicações e frameworks compatíveis com CUDA |
| Escalabilidade | Permite que múltiplas GPUs se comportem mais como uma única GPU grande |
** Por que o NVLink é Importante para LLMs e IA **
- Paralelismo de Modelo: Modelos grandes (ex: LLMs estilo GPT) são grandes demais para uma única GPU. O NVLink permite que as GPUs compartilhem memória e carga de trabalho de forma eficiente.
- Treinamento e Inferência Mais Rápidos: Reduz os gargalos de comunicação, aumentando o desempenho em sistemas multi-GPU.
- Acesso Unificado à Memória: Torna a transferência de dados entre GPUs quase transparente comparado ao PCIe, melhorando a sincronização e a vazão.
- Treinamento com Várias Placas: Para treinamento distribuído entre múltiplas GPUs, a largura de banda da comunicação se torna crucial.
Tabela Resumo: Importância da Comunicação Entre GPUs no Treinamento Distribuído
( Tabela: Papel da Comunicação Entre GPUs no Treinamento Distribuído. Esta tabela descreve onde a comunicação rápida GPU a GPU é necessária e por que é crítica para o treinamento escalável e eficiente de modelos de deep learning. )
| Tarefa de Treinamento Distribuído | Por que a Comunicação Entre GPUs Importa |
|---|---|
| Sincronização de gradientes | Garante consistência e convergência em configurações de paralelismo de dados |
| Fragmentação de modelo | Permite o fluxo de dados transparente em arquiteturas de paralelismo de modelo |
| Atualizações de parâmetros | Mantém os pesos do modelo sincronizados entre GPUs |
| Escalabilidade | Permite o uso eficiente de GPUs ou nós adicionais |
| Desempenho | Reduz o tempo de treinamento e maximiza a utilização do hardware |
4. Consumo de Energia e Refrigeração
- TDP (Thermal Design Power): GPUs de maior desempenho requerem mais energia e geram mais calor.
- Soluções de Refrigeração: Garanta que seu sistema de refrigeração possa lidar com a saída de calor de múltiplas GPUs de alto desempenho.
Opções Populares de GPU Comparadas
** Tabela: Comparação de Funcionalidades de GPUs NVIDIA para Deep Learning. Esta tabela compara as principais especificações e capacidades das RTX 4090, RTX A6000 e RTX 6000 Ada, destacando seus pontos fortes para cargas de trabalho de deep learning. **
| Funcionalidade | RTX 4090 | RTX A6000 | RTX 6000 Ada |
|---|---|---|---|
| Arquitetura | Ada Lovelace | Ampere | Ada Lovelace |
| Ano de Lançamento | 2022 | 2020 | 2022 |
| Memória da GPU (VRAM) | 24 GB GDDR6X | 48 GB GDDR6 ECC | 48 GB GDDR6 ECC |
| Desempenho FP32 | ~83 TFLOPS | ~38.7 TFLOPS | ~91.1 TFLOPS |
| Desempenho Tensor | ~330 TFLOPS (FP16, sparsity enabled) | ~312 TFLOPS (FP16, sparsity) | ~1457 TFLOPS (FP8, sparsity) |
| Suporte a Tensor Core | 4ª Geração (com FP8) | 3ª Geração | 4ª Geração (com suporte a FP8) |
| Suporte a NVLink | ❌ (Sem NVLink) | ✅ (NVLink 2-way) | ✅ (NVLink 2-way) |
| Consumo de Energia (TDP) | 450W | 300W | 300W |
| Fator de Forma | Consumidor (2-slot) | Workstation (2-slot) | Workstation (2-slot) |
| Suporte a Memória ECC | ❌ | ✅ | ✅ |
| Mercado Alvo | Entusiasta / Prosumer | Profissional / Ciência de Dados | Corporativo / Workstation de IA |
| **Preço sugerido (aprox.) em USD |