
Anthropic Apresenta Claude Sonnet 4.5: Mais Rápido, Mais Inteligente, Mas Ainda em Segundo Lugar na Corrida do Código
O novo LLM mostra progresso real em tarefas longas e complexas e suporte à codificação, mas ainda tem dificuldades para igualar o GPT-5 Codex nos problemas mais difíceis.
SAN FRANCISCO — A Anthropic lançou seu mais recente modelo de IA, Claude Sonnet 4.5, na segunda-feira com declarações ousadas. A empresa o chamou de “o melhor modelo de codificação do mundo.” Mas uma análise mais detalhada revela uma história diferente. Sim, o modelo é mais rápido e mais resiliente que seus predecessores. No entanto, testes independentes mostram que ele ainda fica aquém do GPT-5 Codex da OpenAI em áreas cruciais que mais importam para desenvolvedores profissionais.
O lançamento ocorreu apenas quatro meses após o Sonnet 4, um lembrete de quão rapidamente as empresas de IA estão competindo para superar umas às outras. Anthropic e OpenAI agora lançam grandes atualizações quase a cada trimestre. Observadores notaram que a Anthropic frequentemente sincroniza seus anúncios para ofuscar a OpenAI. Por exemplo, o Opus 4.1 da Anthropic foi lançado pouco antes do GPT-5 em agosto.
Construído para Resistência, Não Apenas Velocidade
A Anthropic está apostando alto na resistência. De acordo com os testes da empresa, o Sonnet 4.5 consegue lidar com projetos de codificação complexos por mais de 30 horas consecutivas sem perder o foco. Isso representa um avanço em relação a modelos mais antigos, que tendiam a se desviar da tarefa durante sessões longas.
Os números comprovam isso. No SWE-bench Verified — um benchmark que mede o desempenho de engenharia de software no mundo real — o Sonnet 4.5 obteve uma pontuação mais alta do que qualquer modelo anterior da Anthropic. No OSWorld, que testa a capacidade da IA de lidar com sistemas de computador completos, ele saltou de 42,2% em junho para 61,4% hoje.
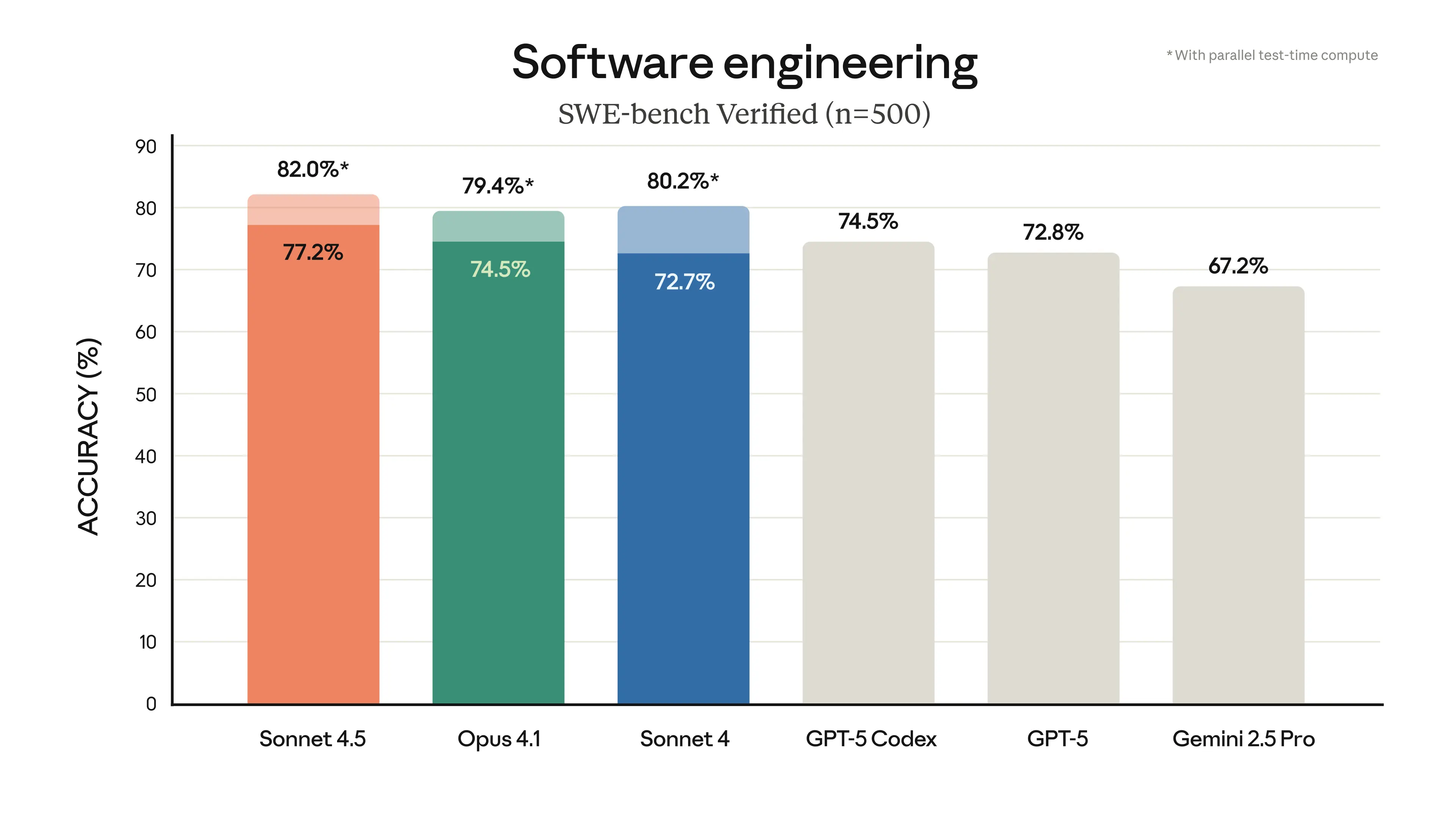
Na prática, isso significa que o modelo agora pode fazer mais do que apenas escrever código. Ele pode navegar em navegadores da web, preencher planilhas e até mesmo completar formulários online extensos usando a extensão para Chrome da Anthropic. Os desenvolvedores também recebem novas ferramentas como pontos de verificação (checkpoints) no Claude Code, que permitem salvar o progresso sem Git, um terminal mais elegante e integração nativa com o Visual Studio Code.
O Confronto com a Realidade
Engenheiros da nossa equipe de engenharia da CTOL.digital elogiaram sua velocidade e confiabilidade para o trabalho diário — tarefas como revisar pull requests, depurar e gerenciar projetos com múltiplos arquivos. O recurso de checkpoint, em particular, recebeu muitos elogios.
Mas a lua de mel terminou quando eles pediram para o modelo lidar com desafios mais difíceis. Trabalhos complexos de front-end o fizeram tropeçar. Em alguns casos, ele ignorou a estrutura existente de um projeto ou a configuração de autenticação, o que pode quebrar aplicativos de maneiras que nenhum desenvolvedor deseja.
“Para codificação diária, é excelente”, explicou um engenheiro da nossa equipe de engenharia. “Mas quando estamos diante de quebra-cabeças lógicos complexos ou bugs de produção espinhosos, o GPT-5 Codex ainda é nossa primeira escolha.”
A conclusão? Muitos membros da equipe se veem usando um sistema de dois modelos: utilizando o Sonnet 4.5 para tarefas rotineiras e entregando as tarefas mais difíceis ao GPT-5. Essa abordagem poderia equilibrar custos e produtividade até que a Anthropic diminua a diferença.
Construindo para o Futuro dos Agentes
Além do próprio modelo, a Anthropic está discretamente preparando o terreno para algo maior. A empresa acaba de lançar o Claude Agent SDK, o mesmo kit de ferramentas por trás do Claude Code. Com ele, os desenvolvedores podem construir agentes autônomos que lidam com tarefas de longa duração, gerenciam permissões e coordenam-se entre múltiplos subagentes.
A Anthropic também está realizando uma demonstração de cinco dias, “Imagine com Claude”, para usuários premium. Nela, o Sonnet 4.5 constrói software real e funcional do zero, ao vivo e sem roteiro. Embora posicionado como um experimento, isso sugere a ambição da empresa de ir além dos assistentes de codificação e em direção a colaboradores de IA completos.
Os preços permanecem os mesmos — US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída — mantendo o Claude firmemente no nível premium, enquanto os concorrentes cortam as tarifas.
Segurança Ainda em Destaque
A Anthropic não esqueceu o alinhamento. O Sonnet 4.5 é apresentado como seu modelo mais seguro até agora, mostrando menos sinais de lisonja, engano ou outros comportamentos de risco. Ele também resiste melhor a ataques de injeção de prompt do que antes, o que é crucial quando os agentes operam dentro de sistemas reais.
O modelo vem com proteções de Nível 3 de Segurança da IA, incluindo filtros que detectam entradas perigosas relacionadas ao desenvolvimento de armas. Esses filtros às vezes bloqueiam material inofensivo, mas a Anthropic afirma que os alarmes falsos diminuíram dez vezes desde as versões anteriores.
Pressão de Todos os Lados
A sobrevivência da Anthropic parece menos precária após este lançamento, mas a ameaça permanece. Ela já perdeu sua posição de joia da coroa como o melhor LLM de codificação — nossos problemas mais difíceis agora são solucionáveis apenas com o GPT-5 High/Pro. Neste ponto, a Anthropic só pode competir em preço e casos de uso diários. Mas se o Gemini 3 superar o Sonnet 4.5 em codificação e também for mais barato — permanecendo na fronteira de Pareto — a Anthropic poderá estar em sérios apuros, já que a maior vantagem de seus modelos até agora tem sido em tarefas de codificação diárias.
Investidores, Atenção
Para os investidores, a mensagem é clara: o mercado de grandes modelos de linguagem está amadurecendo rapidamente. Os ganhos agora são incrementais, e a verdadeira diferenciação pode em breve vir da integração, do bloqueio do ecossistema (ecosystem lock-in) ou do ajuste fino (fine-tuning) específico da indústria — não do poder bruto.
Os desenvolvedores, enquanto isso, dificilmente se limitarão a um único fornecedor. A jogada mais inteligente é misturar e combinar modelos dependendo da tarefa. Isso poderia espremer os lucros dos criadores de modelos, mas criar oportunidades para empresas que desenvolvem ferramentas de orquestração.
O risco é mais acentuado para as empresas que vendem apenas modelos de base (foundation models). À medida que os recursos convergem e os clientes mudam facilmente, o poder de precificação pode entrar em colapso muito antes que os custos operacionais o façam. Hyperscalers, com seus bolsos fundos e pacotes de nuvem, poderiam acelerar essa tendência.
Aviso: Este artigo reflete as condições atuais e os padrões de mercado. Resultados passados não garantem desempenho futuro. Os leitores devem procurar aconselhamento financeiro independente antes de tomar decisões de investimento.